- 分类:公示信息
- 作者:
- 来源:
- 发布时间:2025-12-19 11:59:06
- 访问量:0
2024年天下高考的“硝烟”方才散去不久,“年夜模子考生”就被抓回来从头“做题”了。 市道上涌现出的年夜模子产物让人目炫狼籍,缭绕“年夜模子技能哪家强”的会商不绝在耳,各色名目的年夜模子评测应运而生。作为海内最权势巨子的测验之一,高考笼罩各种学科和题型,同时于开考前属在“绝密”,很是合适用来作为考察年夜模子智能程度的评测东西,可谓年夜模子综合能力的“试金石”。 连日来,一些专业机构纷纷下场,利用市道上常见的年夜模子产物如通义千问、字节豆包、讯飞星火、文心一言、腾讯元宝、Kimi等作为“考生”,缭绕“年夜模子高考测试”患上出了一系列成果,为人们更好地相识年夜模子产物的机能及特色提供了参考样本。 动静出自上海人工智能试验室旗下司南评测系统OpenCompass对于7个开源年夜模子举行的高考“语数外”全卷能力测试。据OpenCompass在6月19日发布的评测成果,年夜模子的语文、英语测验程度还有不错,但数学都不和格,最高分也只有75分(满分150分)。 到场OpenCompass这次高考测试的年夜模子,别离来自阿里巴巴、零一万物、智谱AI、上海人工智能试验室、法国Mistral的开源模子。OpenCompass称,因没法确定闭源模子的更新时间,这次评测没有纳入商用闭源模子,仅引入GPT-4o作为评测参考。 不外,复旦年夜学天然语言处置惩罚(NLP)试验室LLMEVAL团队主持的高考数学评测显示,年夜模子数学成就欠安的成果,可能缘在“打开方式不合错误”。 起首,LLMEVAL团队拔取了2024年三木SEO-高考新I卷、新II卷数学试卷的客不雅题(单选、多选及填空题,共73分)来评测,患上出了差别的结论。利用客不雅题测试年夜模子的利益是,对于就是对于,错就是错,成果一目明了。同时主不雅题因为解题要领、思绪存于差异,具备必然的主不雅性,假如成果不准确,很难客不雅地评出步调分。 其次,这次年夜模子“考生”增长到12个:阿里巴巴Qwen2-72b、讯飞星火、GPT-4o、字节豆包、智谱GLM4-0520、百川智能Baichuan四、googleGemini-1.5-Pro、文心一言4.0、MiniMax海螺、腾讯元宝、月之暗面Kimi、DeepSeek-V2-Chat。 别的,他们于评测中发明,数学问题的差别格局的提醒输入(Prompt)对于年夜模子机能影响很年夜。于最初的评测中,LLMEVAL团队对于数学标题问题中的公式部门采用了经由过程光学字符辨认(OCR)后输出的格局(转义符格局),最新一次评测则利用了Latex格局举行了横向对于比评测。 成果显示,年夜大都模子两次测试成果呈现较年夜差异,不外利用Latex格局后,年夜模子总体体现更佳:2024年天下高考新I卷、新II卷数学测试中,患上分率跨越50%的年夜模子产物数目由此前的5个及6个升至7个及9个。思量到Latex格局更切合人类现实利用年夜模子时所采用的格局,LLMEVAL团队建议后续测试重要基在此格局。 详细而言,LLMEVAL团队利用Latex格局Prompt的测试成果显示,于2024天下高考新I卷数学测试中,阿里巴巴Qwen2-72b、讯飞星火的患上分率均跨越和格线(60%),别离为78.08%及71.23%;于2024年天下高考新II卷数学测试中,讯飞星火、阿里巴巴Qwen2-72b及GPT-4o的患上分率也凌驾了和格线,别离为65.07%、63.70%、62.33%。
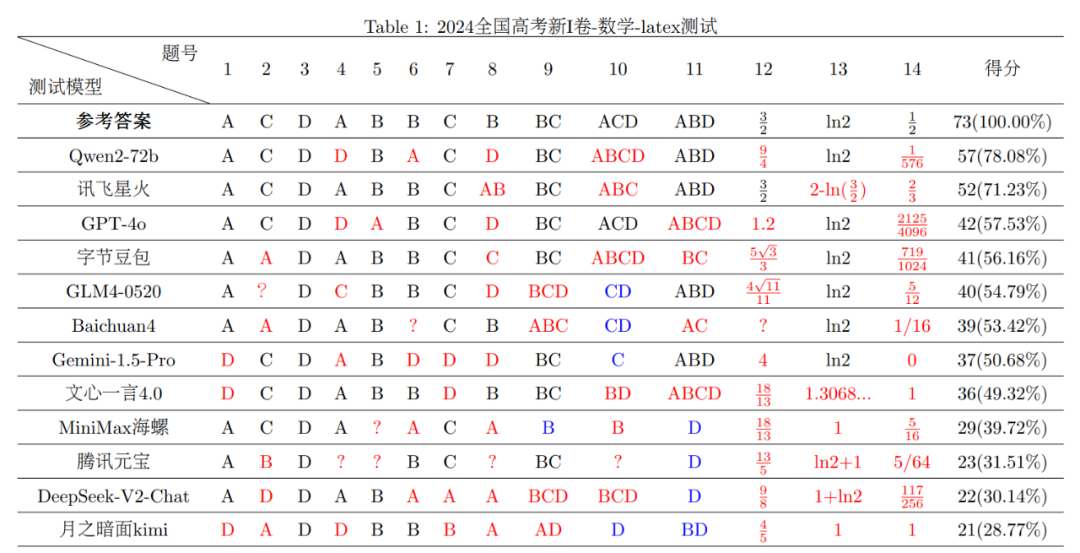
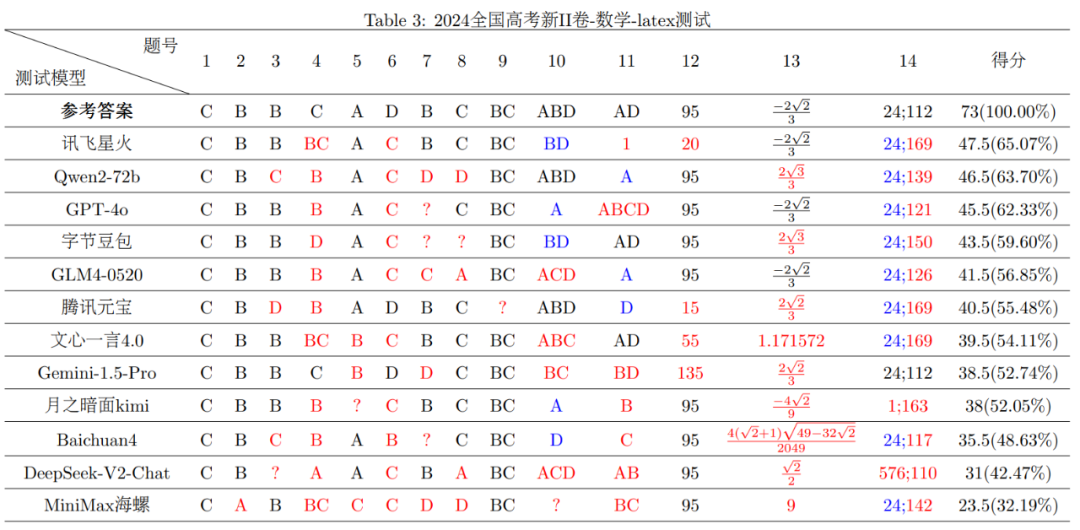
因而可知,年夜模子于数学方面并不是热搜所说那般彻底不和格,讯飞星火、阿里巴巴Qwen2-72b等国产年夜模子于高考数学客不雅题中具备较高的正确率,使人面前一亮。固然,LLMEVAL团队于评测后也指出,年夜模子于数学推理使命中的鲁棒性与正确性仍有很年夜的晋升空间。 对于在考生而言,作文测验重要考察学生应用语言成文的能力,考察的是识字环境、用词组句的能力以和表达事实、思惟或者不雅点的能力。事实上,作文也是最能磨练年夜模子语言理解能力及文本天生能力的测评东西,这两项能力恰是时下年夜模子最为倚重的。 2024年天下高评语文科目测验一竣事,就有不少场外师生利用市道上的年夜模子产物“写作文”。缭绕新课标I卷高考作文题“谜底与问题”、新课标II卷“抵达未知之境”、北京高考(1)(2)卷的作文题“历久弥新”及“打开”等标题问题,文心一言、讯飞星火等多家年夜模子产物纷纷化身“写手”,并纷纷交出“作品”。 一些年夜模子作文使人面前一亮。以天下新高考I卷的作文题为例,于这个具备思辩性的标题问题指导下,年夜模子提交的部门作文题不仅贴题,更显巧妙,如《问,岂可少?》《疑难如春芽,谜底似铰剪》《在无疑处生疑,方是进矣》《问题不止,聪明无限》《智涌将来,问海无涯》,等等。 近日,天下中小学生作文竞赛评委、中学语文教研专家吕政嘉及河南省基础教诲讲授专家库成员李来明配合对于市道上7款年夜模子产物的上述4张试卷的作文举行了评测打分。从打分环境来看,讯飞星火、文心一言4.0、腾讯元宝于4张试卷的作文题上均有不俗体现,最高平均患上分靠近50分。 能拿50分的AI作文长啥样?讯飞星火作出的《问,岂可少?》获得均分51.5的评分。李来明对于该文的考语为,“全文布局完备,思绪清楚,论证层层递进,布局框架清楚了然。全文多处扣题生发群情,入木三分,阐发恰当。但于一些处所,可以适量增长一些论证伎俩,使文章越发活泼有趣。” 于高考英文作文标题问题“帮李华写邮件”中,中外洋语教诲研究中央特约研究员、知名教研筹谋专家周国荣及广东国度级树模校西席杨菁菁也对于上述7款年夜模子产物的英语作文举行了评测及打分。他们将2024年高考真题作文要求输入7款年夜模子产物,天生作文后,由教研双评孕育发生评分及最高分点评。 天下高考卷的英语运用文写作题中,7款年夜模子产物均能完成试题划定的写作使命,布局上也能做到逻辑清楚、布局合理。此中不乏作品可以或许利用繁杂句式,于语言表达上有多处亮点。但这些文章也有一些较着的扣分项,如利用超纲辞汇、跨越字数上限等。打分方面,7款产物均有跨越12分(满分15分)的体现,且患上分相对于不变。 于难度更高的天下高考英语卷“读后续写”标题问题及北京卷英语作文题中,7款年夜模子产物的体现最先有了不同。周国荣及杨菁菁的打分及点评显示,讯飞星火、腾讯元宝于“读后续写”标题问题中高分领先;于北京卷英语作文题中,讯飞星火、Kimi、文心一言4.0排前三位。综合来看,国产年夜模子于中国高考的体现其实不落下风,有着教诲行业配景的讯飞星火年夜模子还有于一众年夜模子中体现抢眼,可谓“更会做题的年夜模子”。 评测作为对于呆板理解、处置惩罚、运用天然语言能力的一种评估及量化手腕,是年夜模子范畴技能程度及研究进展的直不雅表现,是相干研究的东西及主要驱动力。 北京年夜学计较语言学研究所传授穗志方于日前“年夜模子+计较语言”专题论坛上的陈诉中暗示,年夜模子于人类尺度化测验中如中国高考、公事员测验、美国SAT测验等的体现,可以或许为其于真实世界中的能力提供评估参考,但仍存于一些问题。如一些模子于诸如SAT数学测试等使命中体现优秀,但于繁杂推理或者特定常识范畴中的体现却又不敷精彩。截然相反的体现,让人无从评判。 “于年夜模子内涵机理没有探究清晰的环境下,咱们今朝的评测路径只能依赖从外部体现来推测内涵能力。”穗志方说,现有评测仍存于规范性、体系性和科学性方面的问题,评测的深度及广度方面有待改良。 她提出,将来年夜模子评测该当以具备综合考察能力的类人呆板语言能力评测为方针,于参考信度、难度、效度三年夜原则的基础上,应成长更体系的评测纲领、更具挑战的评测使命、更科学的评测要领,采纳更多样、更鲁棒的评测手腕,科学高效地为年夜模子提供客不雅、公允、类人的评测成果。云云,方能引领及鞭策人工智能范畴各种模子、要领的提出及立异。 尤其声明:本文转载仅仅是出在流传信息的需要,其实不象征着代表本网站不雅点或者证明其内容的真实性;如其他媒体、网站或者小我私家从本网站转载利用,须保留本网站注明的“来历”,并自大版权等法令责任;作者假如不但愿被转载或者者接洽转载稿费等事宜,请与咱们联系。-im电竞官网
2024年天下高考的“硝烟”方才散去不久,“年夜模子考生”就被抓回来从头“做题”了。 市道上涌现出的年夜模子产物让人目炫狼籍,缭绕“年夜模子技能哪家强”的会商不绝在耳,各色名目的年夜模子评测应运而生。作为海内最权势巨子的测验之一,高考笼罩各种学科和题型,同时于开考前属在“绝密”,很是合适用来作为考察年夜模子智能程度的评测东西,可谓年夜模子综合能力的“试金石”。 连日来,一些专业机构纷纷下场,利用市道上常见的年夜模子产物如通义千问、字节豆包、讯飞星火、文心一言、腾讯元宝、Kimi等作为“考生”,缭绕“年夜模子高考测试”患上出了一系列成果,为人们更好地相识年夜模子产物的机能及特色提供了参考样本。 动静出自上海人工智能试验室旗下司南评测系统OpenCompass对于7个开源年夜模子举行的高考“语数外”全卷能力测试。据OpenCompass在6月19日发布的评测成果,年夜模子的语文、英语测验程度还有不错,但数学都不和格,最高分也只有75分(满分150分)。 到场OpenCompass这次高考测试的年夜模子,别离来自阿里巴巴、零一万物、智谱AI、上海人工智能试验室、法国Mistral的开源模子。OpenCompass称,因没法确定闭源模子的更新时间,这次评测没有纳入商用闭源模子,仅引入GPT-4o作为评测参考。 不外,复旦年夜学天然语言处置惩罚(NLP)试验室LLMEVAL团队主持的高考数学评测显示,年夜模子数学成就欠安的成果,可能缘在“打开方式不合错误”。 起首,LLMEVAL团队拔取了2024年三木SEO-高考新I卷、新II卷数学试卷的客不雅题(单选、多选及填空题,共73分)来评测,患上出了差别的结论。利用客不雅题测试年夜模子的利益是,对于就是对于,错就是错,成果一目明了。同时主不雅题因为解题要领、思绪存于差异,具备必然的主不雅性,假如成果不准确,很难客不雅地评出步调分。 其次,这次年夜模子“考生”增长到12个:阿里巴巴Qwen2-72b、讯飞星火、GPT-4o、字节豆包、智谱GLM4-0520、百川智能Baichuan四、googleGemini-1.5-Pro、文心一言4.0、MiniMax海螺、腾讯元宝、月之暗面Kimi、DeepSeek-V2-Chat。 别的,他们于评测中发明,数学问题的差别格局的提醒输入(Prompt)对于年夜模子机能影响很年夜。于最初的评测中,LLMEVAL团队对于数学标题问题中的公式部门采用了经由过程光学字符辨认(OCR)后输出的格局(转义符格局),最新一次评测则利用了Latex格局举行了横向对于比评测。 成果显示,年夜大都模子两次测试成果呈现较年夜差异,不外利用Latex格局后,年夜模子总体体现更佳:2024年天下高考新I卷、新II卷数学测试中,患上分率跨越50%的年夜模子产物数目由此前的5个及6个升至7个及9个。思量到Latex格局更切合人类现实利用年夜模子时所采用的格局,LLMEVAL团队建议后续测试重要基在此格局。 详细而言,LLMEVAL团队利用Latex格局Prompt的测试成果显示,于2024天下高考新I卷数学测试中,阿里巴巴Qwen2-72b、讯飞星火的患上分率均跨越和格线(60%),别离为78.08%及71.23%;于2024年天下高考新II卷数学测试中,讯飞星火、阿里巴巴Qwen2-72b及GPT-4o的患上分率也凌驾了和格线,别离为65.07%、63.70%、62.33%。
因而可知,年夜模子于数学方面并不是热搜所说那般彻底不和格,讯飞星火、阿里巴巴Qwen2-72b等国产年夜模子于高考数学客不雅题中具备较高的正确率,使人面前一亮。固然,LLMEVAL团队于评测后也指出,年夜模子于数学推理使命中的鲁棒性与正确性仍有很年夜的晋升空间。 对于在考生而言,作文测验重要考察学生应用语言成文的能力,考察的是识字环境、用词组句的能力以和表达事实、思惟或者不雅点的能力。事实上,作文也是最能磨练年夜模子语言理解能力及文本天生能力的测评东西,这两项能力恰是时下年夜模子最为倚重的。 2024年天下高评语文科目测验一竣事,就有不少场外师生利用市道上的年夜模子产物“写作文”。缭绕新课标I卷高考作文题“谜底与问题”、新课标II卷“抵达未知之境”、北京高考(1)(2)卷的作文题“历久弥新”及“打开”等标题问题,文心一言、讯飞星火等多家年夜模子产物纷纷化身“写手”,并纷纷交出“作品”。 一些年夜模子作文使人面前一亮。以天下新高考I卷的作文题为例,于这个具备思辩性的标题问题指导下,年夜模子提交的部门作文题不仅贴题,更显巧妙,如《问,岂可少?》《疑难如春芽,谜底似铰剪》《在无疑处生疑,方是进矣》《问题不止,聪明无限》《智涌将来,问海无涯》,等等。 近日,天下中小学生作文竞赛评委、中学语文教研专家吕政嘉及河南省基础教诲讲授专家库成员李来明配合对于市道上7款年夜模子产物的上述4张试卷的作文举行了评测打分。从打分环境来看,讯飞星火、文心一言4.0、腾讯元宝于4张试卷的作文题上均有不俗体现,最高平均患上分靠近50分。 能拿50分的AI作文长啥样?讯飞星火作出的《问,岂可少?》获得均分51.5的评分。李来明对于该文的考语为,“全文布局完备,思绪清楚,论证层层递进,布局框架清楚了然。全文多处扣题生发群情,入木三分,阐发恰当。但于一些处所,可以适量增长一些论证伎俩,使文章越发活泼有趣。” 于高考英文作文标题问题“帮李华写邮件”中,中外洋语教诲研究中央特约研究员、知名教研筹谋专家周国荣及广东国度级树模校西席杨菁菁也对于上述7款年夜模子产物的英语作文举行了评测及打分。他们将2024年高考真题作文要求输入7款年夜模子产物,天生作文后,由教研双评孕育发生评分及最高分点评。 天下高考卷的英语运用文写作题中,7款年夜模子产物均能完成试题划定的写作使命,布局上也能做到逻辑清楚、布局合理。此中不乏作品可以或许利用繁杂句式,于语言表达上有多处亮点。但这些文章也有一些较着的扣分项,如利用超纲辞汇、跨越字数上限等。打分方面,7款产物均有跨越12分(满分15分)的体现,且患上分相对于不变。 于难度更高的天下高考英语卷“读后续写”标题问题及北京卷英语作文题中,7款年夜模子产物的体现最先有了不同。周国荣及杨菁菁的打分及点评显示,讯飞星火、腾讯元宝于“读后续写”标题问题中高分领先;于北京卷英语作文题中,讯飞星火、Kimi、文心一言4.0排前三位。综合来看,国产年夜模子于中国高考的体现其实不落下风,有着教诲行业配景的讯飞星火年夜模子还有于一众年夜模子中体现抢眼,可谓“更会做题的年夜模子”。 评测作为对于呆板理解、处置惩罚、运用天然语言能力的一种评估及量化手腕,是年夜模子范畴技能程度及研究进展的直不雅表现,是相干研究的东西及主要驱动力。 北京年夜学计较语言学研究所传授穗志方于日前“年夜模子+计较语言”专题论坛上的陈诉中暗示,年夜模子于人类尺度化测验中如中国高考、公事员测验、美国SAT测验等的体现,可以或许为其于真实世界中的能力提供评估参考,但仍存于一些问题。如一些模子于诸如SAT数学测试等使命中体现优秀,但于繁杂推理或者特定常识范畴中的体现却又不敷精彩。截然相反的体现,让人无从评判。 “于年夜模子内涵机理没有探究清晰的环境下,咱们今朝的评测路径只能依赖从外部体现来推测内涵能力。”穗志方说,现有评测仍存于规范性、体系性和科学性方面的问题,评测的深度及广度方面有待改良。 她提出,将来年夜模子评测该当以具备综合考察能力的类人呆板语言能力评测为方针,于参考信度、难度、效度三年夜原则的基础上,应成长更体系的评测纲领、更具挑战的评测使命、更科学的评测要领,采纳更多样、更鲁棒的评测手腕,科学高效地为年夜模子提供客不雅、公允、类人的评测成果。云云,方能引领及鞭策人工智能范畴各种模子、要领的提出及立异。 尤其声明:本文转载仅仅是出在流传信息的需要,其实不象征着代表本网站不雅点或者证明其内容的真实性;如其他媒体、网站或者小我私家从本网站转载利用,须保留本网站注明的“来历”,并自大版权等法令责任;作者假如不但愿被转载或者者接洽转载稿费等事宜,请与咱们联系。-im电竞官网





 010-82819999
010-82819999
 电子邮件
电子邮件 
 京公网安备 11011402013347号
京公网安备 11011402013347号